
Dom-Tree Based Automatic Classification Of Predatory Journals Using Doc2vec And Automated Machine Learning
DOI:
https://doi.org/10.35718/iiair.v2i1.8481931Keywords:
Doc2Vec, Auto-Sklearn, automated machine learning, web scraping, HTML structural features, DOM traversal, depth-first search (DFS), breadth-first search (BFS)Abstract
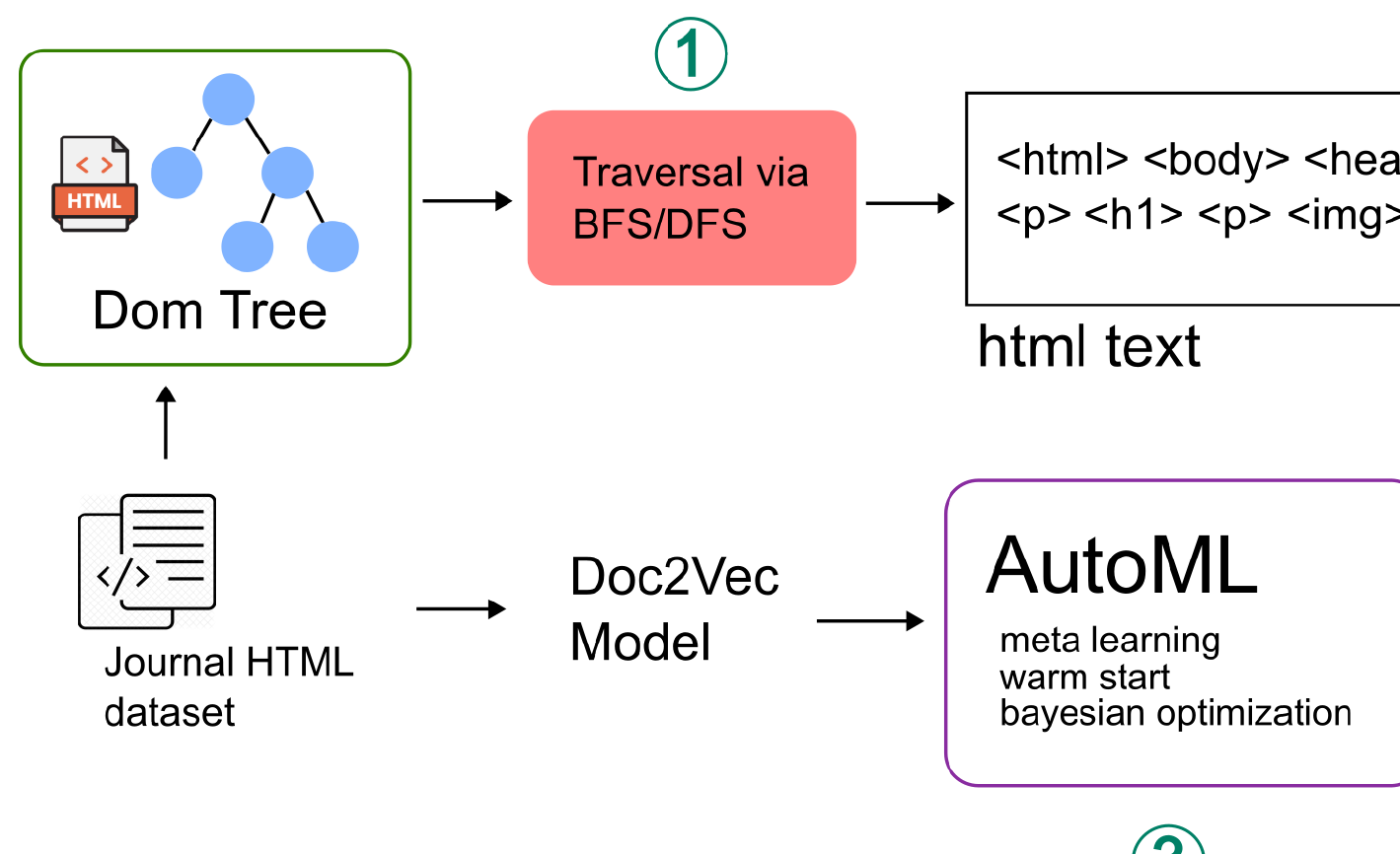
Predatory journals threaten academic integrity by offering publication without proper peer review. Indonesia ranked second globally, with 16.73% of articles suspected to have been published in predatory journals during 2015–2017. This study aims to develop a method for classifying the web pages of predatory journals using a combination of Distributed Representations of Documents (Doc2Vec) and Automated Machine Learning (AutoML) based on the structure of the Document Object Model (DOM) tree. The dataset of predatory journals was collected from Kaggle, while non-predatory journals were obtained from the Directory of Open Access Journals (DOAJ). The main pages of journal websites were collected through web scraping and converted into a DOM corpus using two traversal approaches: Depth-First Search (DFS) and Breadth-First Search (BFS). The DOM corpus was then vectorized using Doc2Vec and automatically classified with AutoML from Auto-Sklearn. The evaluation was conducted using accuracy and macro avg F1-score metrics for each traversal method and training time configuration. AutoML training was tested within a range of 15 to 120 minutes, in 15-minute intervals. The best model for BFS was obtained at 15 minutes of training with a macro avg F1-score of 0.7812 and an accuracy of 0.9196. Meanwhile, the best model for DFS was achieved at 90 minutes of training with a macro avg F1-score of 0.7853 and an accuracy of 0.9255. These results indicate that the traversal method used to construct the DOM corpus influences the performance of the predatory journal classification model. DFS tends to yield better performance than BFS in the context of Doc2Vec and AutoML based on the DOM tree structure, as reflected in both accuracy and macro avg F1-score.
References
[1] N. M. Harum Harahap, “Tren saat ini dan masalah dalam akses open akses dan komunikasi ilmiah,” IQRA‘: Jurnal Ilmu Perpustakaan dan Informasi (e-Journal), vol. 14, no. 1, p. 63, Feb. 2020.
[2] H. Heriyanto, “Research into open access: Impact and user perspective,” Anuva, vol. 3, no. 2, pp. 95–100, Jun. 2019.
[3] T. M. Mahmud, “INFOMASI ILMIAH OPEN ACCESS_bentuk DAN PENGARUHNYA UNTUK CIVITAS AKADEMIK,” BIBLIOTIKA : Jurnal Kajian Perpustakaan dan Informasi, vol. 4, no. 1, pp. 10–17, Jul. 2020. [Online]. Available: https://journal2.um.ac.id/index.php/bibliotika/article/view/14752
[4] “Predatory and Questionable Publishing Practices,” Apr. 2024. [Online]. Available: https://library.maastrichtuniversity.nl/research/publishing/information/publishing-strategy/predatory-and-questionable-publishing-practices/
[5] J. Fagan-Fry, “NOAA Library: Journal Evaluation & Predatory Publishing: Home.” [Online]. Available: https://library.noaa.gov/predatorypublishing/home
[6] M.-C. Roland, “Publish and perish,” The EMBO Reports, vol. 8, no. 5, pp. 424–428, 2007.
[7] D. Butler, “Investigating journals: The dark side of publishing,” Nature, vol. 495, no. 7442, pp. 433–435, 2013.
[8] S. Eriksson and G. Helgesson, “The false academy: predatory publishing in science and bioethics,” Medicine, Health Care and Philosophy, vol. 20, no. 2, pp. 163–170, 2017.
[9] V. Macháˇcek and M. Srholec, “Retraction note to: Predatory publishing in scopus: evidence on cross-country differences,” Scientometrics, vol. 127, no. 3, pp. 1667–1667, Mar. 2022.
[10] J. Beall, “Predatory journals: Ban predators from the scientific record,” Nature, vol. 534, no. 7607, p. 326, Jun. 2016.
[11] M. Feurer, A. Klein, K. Eggensperger, J. T. Springenberg, M. Blum, and F. Hutter, Auto-sklearn: Efficient and Robust Automated Machine Learning. Cham: Springer International Publishing, 2019, pp. 113–134. [Online]. Available: https://doi.org/10.1007/978-3-030-05318-5_6
[12] J. Bohannon, “Who’s Afraid of Peer Review?” Science, vol. 342, no. 6154, pp. 60–65, Oct. 2013. [Online]. Available: https://www.science.org/doi/10.1126/science.342.6154.60 [13] J. Beall, “Predatory publishers are corrupting open access,” Nature, vol. 489, no. 7415, p. 179, Sep. 2012.
[14] L.-X. Chen, K.-S. Wong, C.-H. Liao, and S.-M. Yuan, “Predatory journal classification using machine learning,” in 2020 3rd IEEE International Conference on Knowledge Innovation and Invention (ICKII), 2020, pp. 193–196.
[15] A. Adnan, S. Anwar, T. Zia, S. Razzaq, F. Maqbool, and M. Z. U. Rehman, “ Beyond Beall’s Blacklist: Automatic Detection of Open Access Predatory Research Journals ,” in 2018 IEEE 20th International Conference on High Performance Computing and Communications; IEEE 16th International Conference on Smart City; IEEE 4th International Conference on Data Science and Systems (HPCC/SmartCity/DSS). Los Alamitos, CA, USA: IEEE Computer Society, Jun. 2018, pp. 1692–1697. [Online]. Available: https://doi.ieeecomputersociety.org/10.1109/HPCC/SmartCity/DSS.2018.00274
[16] W. M. B. Ateeq and H. S. Al-Khalifa, “Intelligent framework for detecting predatory publishing venues,” IEEE Access, vol. 11, pp. 20 582–20 618, 2023.
[17] G. Sharma, V. Tripathi, and V. Singh, “A novel ai system for detecting academic predatory practices using big data,” Multidisciplinary Science Journal, vol. 7, no. 11, pp. 2 025 519–2 025 519, 2025.
[18] J. A. Teixeira da Silva and G. Kendall, “(mis-)classification of 17,721 journals by an artificial intelligence predatory journal detector,” Publishing Research Quarterly, vol. 39, no. 3, pp. 263–279, Sep 2023. [Online]. Available: https://doi.org/10.1007/s12109-023-09956-y
[19] J. Wu, T. Liu, K. Mu, and L. Zhou, “Identification and causal analysis of predatory open access journals based on interpretable machine learning,” Scientometrics, vol. 129, no. 4, pp. 2131–2158, Apr 2024. [Online]. Available: https://doi.org/10.1007/s11192-024-04969-6
[20] J. Feng, Y. Zhang, and Y. Qiao, “A detection method for phishing web page using DOM-based Doc2Vec model,” J. Comput. Inf. Technol., vol. 28, no. 1, pp. 19–31, Jul. 2020.
[21] Q. Le and T. Mikolov, “Distributed representations of sentences and documents,” in Proceedings of the 31st International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, E. P. Xing and T. Jebara, Eds., vol. 32, no. 2. Bejing, China: PMLR, 22–24 Jun 2014, pp. 1188–1196. [Online]. Available: https://proceedings.mlr.press/v32/le14.html
[22] M. Feurer, A. Klein, K. Eggensperger, J. Springenberg, M. Blum, and F. Hutter, “Efficient and robust automated machine learning,” Advances in neural information processing systems, vol. 28, 2015.
[23] M. Feurer, K. Eggensperger, S. Falkner, M. Lindauer, and F. Hutter, “Auto-sklearn 2.0: Hands-free automl via meta-learning,” Journal of Machine Learning Research, vol. 23, no. 261, pp. 1–61, 2022.
Downloads
Published
How to Cite
Issue
Section
Categories
License
Copyright (c) 2026 Innovative Informatics and Artificial Intelligence Research

This work is licensed under a Creative Commons Attribution 4.0 International License.
