
Main Content Extraction from Scientific Journal Websites Using BoilerNet
DOI:
https://doi.org/10.35718/iiair.v2i1.8481487Keywords:
Boilerplate Removal, BoilerNet, Deep Learning, Bi-LSTM, Scientific Journals, Main Content ExtractionAbstract
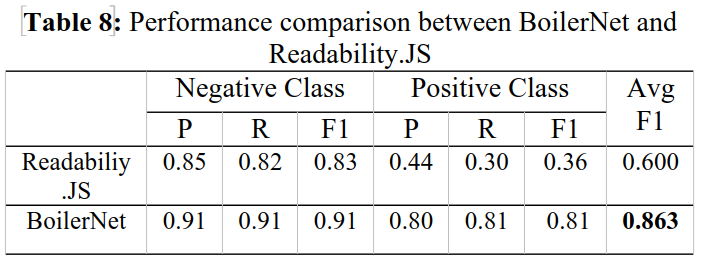
The number of scientific journal publications available online is increasing rapidly. However, information extraction from these journals is often disrupted by boilerplate elements such as headers, footers, navigation bars, and metadata that are not directly related to the main content. The presence of these elements hinders text analysis and further processing in various academic applications. This study aims to investigate an automated boilerplate removal method through BoilerNet, a deep learning model based on the Bi-LSTM approach. BoilerNet is evaluated to classify each text segment in journal pages and accurately separate the main content from boilerplate elements. We also tuned the hyperparameter in BoilerNet to observe its peak capability and compared it with the popular boilerplate removal method, Readibility.JS. Experimental results show that the optimal BoilerNet configuration with 256 hidden units, a dropout rate of 0.4, two LSTM layers, and a dense layer size of 256 achieves an F1 score of 0.91 for the boilerplate class and 0.81 for the main content class. The overall average F1-score reached approximately 0.863. These results indicate that BoilerNet significantly improves main content extraction performance compared to conventional methods such as Readability.JS by 26.3%.
References
[1] J. Leonhardt, A. Anand, and M. Khosla, “Boilerplate Removal using a Neural Sequence Labeling Model,” Companion Proc. Web Conf. 2018, pp. 226–229, 2020. doi: 10.1145/3366424.3383547.
[2] G. Jung, S. Han, H. Kim, K. Kim, and J. Cha, “Extracting the Main Content of Web Pages Using the First Impression Area,” IEEE Access, vol. 10, pp. 129958–129969, 2022. doi: 10.1109/ACCESS.2022.3229080.
[3] J. Alarte and J. Silva, “Page-level main content extraction from heterogeneous webpages,” ACM Trans. Knowl. Discov. Data, vol. 15, no. 6, pp. 1–105, 2021. doi: 10.1145/3451168.
[4] J. Bevendorff, S. Gupta, J. Kiesel, and B. Stein, “An Empirical Comparison of Web Content Extraction Algorithms,” in Proc. 46th ACM SIGIR Conf., 2023. doi: 10.1145/3539618.3591920.
[5] L. Alakukku, “Domain-Specific Boilerplate Removal from Web Pages with Entropy and Clustering,” Tesis, Aalto University, 2022.
[6] E. Akbiyik, J. Almeida, R. Melis, R. Sriram, V. Petrescu, and V. Vilhjálmsson, “Semantic Outlier Removal with Embedding Models and LLMs,” arXiv preprint, arXiv:2506.16644, Jun. 2025. doi: 10.48550/arXiv.2506.16644.
[7] M. Fernández-Pichel and M. Prada-Corral, “An Unsupervised Perplexity-based Method for Boilerplate Removal,” Nat. Lang. Eng., vol. 30, no. 1, 2024. doi: 10.1017/S1351324923000049.
[8] M. J. Hamayel and A. Y. Owda, “A novel cryptocurrency price prediction model using GRU, LSTM and bi-LSTM machine learning algorithms,” AI, vol. 2, no. 4, pp. 477–496, 2021. doi: 10.3390/ai2040030.
[9] Z. Vujovic, “Classification Model Evaluation Metrics,” Int. J. Adv. Comput. Sci. Appl., vol. 12, pp. 599–606, 2021. doi: 10.14569/IJACSA.2021.0120670.
[10] M. Desai and M. Shah, “An anatomization on breast cancer detection and diagnosis employing multi-layer perceptron neural network (MLP) and Convolutional neural network (CNN),” Clin. eHealth, vol. 4, pp. 1–11, 2020. doi: 10.1016/j.ceh.2020.11.002.
[11] A. A. Ifty, “Introduction to the Perceptron and Its Applications,” 2023. doi: 10.13140/RG.2.2.10439.10404.
[12] A. Ismail and K. Kuppusamy, “Web accessibility investigation and identification of major issues of higher education websites with statistical measures: A case study of college websites,” J. King Saud Univ. - Comput. Inf. Sci., vol. 34, no. 3, pp. 901–911, 2019. doi: 10.1016/j.jksuci.2019.03.011.
[13] M. A. Khder, “Web scraping or web crawling: State of art, techniques, approaches and application,” Int. J. Adv. Soft Comput. Appl., vol. 13, no. 11, pp. 1–15, 2021. doi: 10.15849/IJASCA.211128.11.
[14] C. Kohlschütter, P. Fankhauser, and W. Nejdl, “Boilerplate Detection using Shallow Text Features,” in Proc. 3rd ACM Int. Conf. Web Search Data Min. (WSDM '10), pp. 441–450, 2010. doi: 10.1145/1718487.1718542.
[15] B. Lindemann, B. Maschler, N. Sahlab, and M. Weyrich, “A survey on anomaly detection for technical systems using LSTM networks,” Comput. Ind., vol. 131, 2021. doi: 10.1016/j.compind.2021.103498.
[16] C. Muehlethaler and R. Albert, “Collecting data on textiles from the internet using web crawling and web scraping tools,” Forensic Sci. Int., vol. 322, 2021. doi: 10.1016/j.forsciint.2021.110753.
[17] M. Dampfhoffer, T. Mesquida, and J. Kummert, “Backpropagation-based learning techniques for deep spiking neural networks: A survey,” IEEE Trans. Neural Netw. Learn. Syst., 2023. doi: 10.1109/TNNLS.2023.3263008.
[18] K. Sharifani and M. Amini, “Machine Learning and Deep Learning: A Review of Methods and Applications,” World Inf. Technol. Eng. J., vol. 10, no. 7, pp. 3897–3904, 2023. [Online]. Available: https://ssrn.com/abstract=4458723
[19] V. Singrodia, A. Mitra, and S. Paul, “A Review on Web Scraping and its Applications,” in 2019 Int. Conf. Comput. Commun. Informatics (ICCCI), Coimbatore, India, pp. 1–6. doi: 10.1109/ICCCI.2019.8821809.
[20] T. Vogels, O. Ganea, and C. Eickhoff, “Web2Text: Deep structured boilerplate removal,” in Lecture Notes in Computer Science, pp. 167–179, 2018. doi: 10.1007/978-3-319-76941-7_13.
[21] X. Wen and W. Li, “Time Series Prediction Based on LSTM-Attention-LSTM Model,” IEEE Access, vol. 11, pp. 48322–48331, 2023. doi: 10.1109/ACCESS.2023.3276628.
Downloads
Published
How to Cite
Issue
Section
Categories
License
Copyright (c) 2026 Innovative Informatics and Artificial Intelligence Research

This work is licensed under a Creative Commons Attribution 4.0 International License.
